
Introduction
One of the things that makes machine learning hard is that you have to run a lot of experiments. You have to try different models, different data sets, different hyperparameters, different features. And each experiment can take a long time to run, especially if you’re working on deep learning problems. You can’t just run them on your laptop or desktop. You need more computing power, and you need it fast.
But getting more computing power is not easy. You have to deal with cloud providers, set up instances, configure them, launch them, terminate them, and pay for them (1, 2). And you have to keep track of all your experiments and their results. You have to store your data, code, models, and metrics somewhere. You have to be able to compare and reproduce them. You have to avoid losing or forgetting them. Finally, you have to be able to share them with your colleagues and collaborators.
This is where SkyPilot and DVC come in. They are two tools that can help you simplify your machine learning experimentation workflow. Both are designed to be used as command-line tools, but they can also be used as Python libraries:
SkyPilot lets you launch cloud instances for your experiments with a few lines of code.
DVC makes it easy to version-control your machine learning projects. It works with Git to let you track your data, code, models, and metrics in a systematic way.
Together, they can help you run more experiments in less time, and keep track of everything you do and learn. In this blog post, I’ll show you how they work and how they can make your machine learning projects easier and more fun.
Prerequisites
To follow along with this tutorial, you’ll need to have the following installed/configured:
- Python 3.10 or later
- DVC
- SkyPilot
- An existing ML project with a DVC pipeline
dvc.yamlfile. I’ll be using my fork of the DVC example project here - AWS account (configured AWS credentials and access to EC2 and S3)
(Both SkyPilot and DVC work with any major cloud provider, but here I’ll be using AWS)
Quick recap
In this post, I won’t be going into the details of SkyPilot and DVC. The goal of this post is to show you how they can be used together to simplify your computationally intensive ML workflows. If you want to learn about the tools first, check out the quickstart guides for SkyPilot and DVC. That said, below is a quick recap of the main concepts you’ll need to know to follow along. If you are already familiar with both tools, feel free to skip the following two sections and jump right into the section about their integration.
What are DVC pipelines and why would you want to use them?
DVC pipelines allow defining machine learning workflows by connecting data, code
and parameters through reusable stages. The pipeline structure and dependencies
are defined in dvc.yaml. This YAML file sits at the root of the Git
repository. Each stage has a name, command, dependencies and can include metrics
and parameters. For example:
stages:
prepare:
cmd: python prepare.py
deps:
- prepare.py
- data/raw/
outs:
- train.csv
- test.csv
train:
cmd: python train.py
deps:
- train.py
- train.csv
outs:
- model.joblib
evaluate:
cmd: python evaluate.py
deps:
- evaluate.py
- model.joblib
- test.csv
metrics:
- accuracy.json
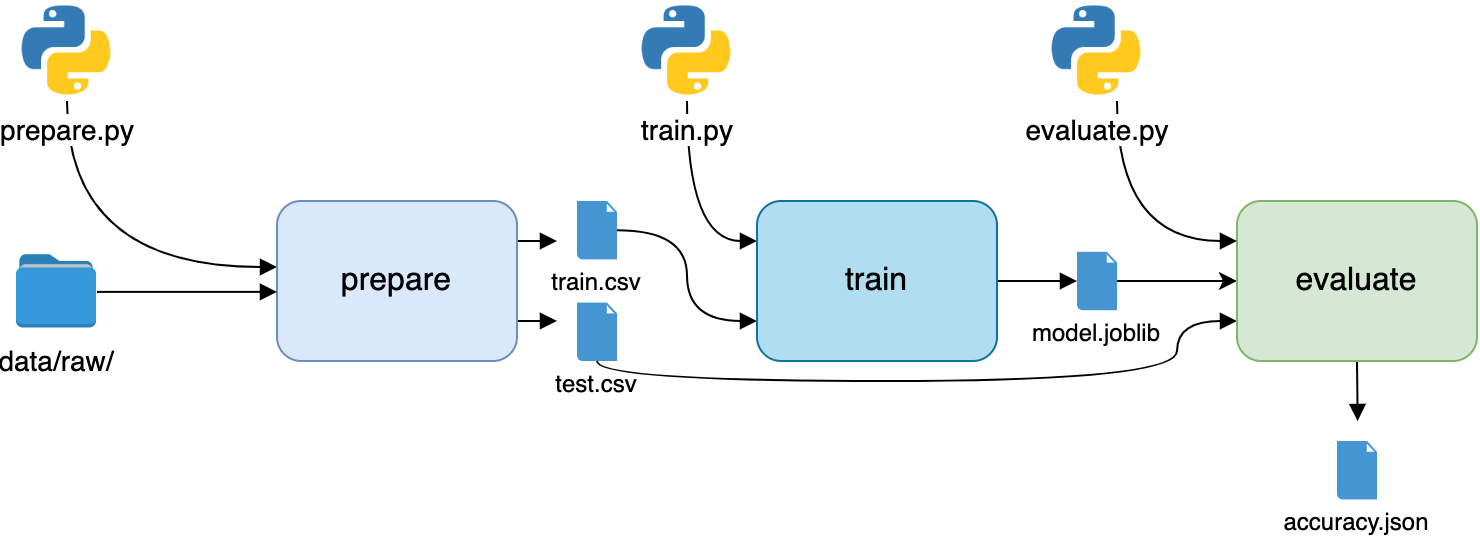 DVC pipeline structure.
Image source: https://realpython.com/python-data-version-control
DVC pipeline structure.
Image source: https://realpython.com/python-data-version-controlThe stages form a directed acyclic
graph that can
be visualized through dvc dag. Dependencies automatically handle data flow.
DVC caches large files and ML artifacts like datasets, models and plots after
the first run. Future runs reuse the cache instead of recomputing, saving time
and storage. The
.dvc
files act as pointers to cached files. Git only tracks the small .dvc files
rather than large binaries. dvc exp run executes necessary
stages when code or parameters change. It provides end-to-end reproducibility
without re-running the whole pipeline.
Here are the key benefits of using DVC for your ML pipelines:
- Organization - DVC organizes workflows into pipelines with stages that have dependencies. This modular structure helps manage complexity.
- Lineage tracking - DVC automatically tracks data lineage from source to output, making it easy to see how data flows through the pipeline.
- Collaboration - DVC enables collaboration by managing a Git repository with small files for metrics, parameters, and code instead of large datasets.
- Cache and storage optimization - DVC efficiently manages storage and optimizes data transfer to avoid repeated computations.
- Reproducibility - DVC pipelines allow you to easily reproduce previous versions of models or results by tracking code, data, and parameters.
The last three points are especially important here as they are the ones that allow us to use SkyPilot to run our experiments in the cloud very easily and efficiently.
What is SkyPilot and why would you want to use it?
SkyPilot is a Python library that lets you launch cloud instances for your experiments with a few lines of code. It works with any major cloud provider, including AWS, GCP, and Azure. It can be used as a command-line tool, but it can also be used as a Python library (which is what I’ll be doing here).
SkyPilot offers multiple benefits for managing cloud infrastructure for machine learning:
- Cloud Abstraction: SkyPilot abstracts away the complexity of managing cloud infrastructures. It gives the ability to launch jobs and clusters on any cloud, automatically manage many jobs, and provide easy access to object stores.
- Maximized GPU Availability: Skypilot provisions GPU across all available zones/regions/clouds ensuring that your jobs always have access to GPU resources with automatic failover.
- Cost Optimization: Skypilot provides cost-saving features such as Managed Spot, the Optimizer, and Autostop, which can significantly cut cloud costs.
- No Code Changes Required: SkyPilot supports existing GPU, TPU, and CPU workloads without the need for code changes. It supports multiple cloud providers including AWS, Azure, GCP, Lambda Cloud, IBM, Samsung, OCI, Cloudflare.
 SkyPilot's usage patterns.
Image source: https://blog.skypilot.co/introducing-skypilot/
SkyPilot's usage patterns.
Image source: https://blog.skypilot.co/introducing-skypilot/For a simple machine learning task, an example SkyPilot YAML might look like this:
resources:
cloud: aws # Optional; if left out, automatically pick the cheapest cloud.
accelerators: V100:1 # 1x NVIDIA V100 GPU
# Working directory (optional) containing the project codebase.
# Its contents are synced to ~/sky_workdir/ on the cluster.
workdir: .
setup: |
pip install -r requirements.txt
run: |
python train.py --epochs 100 --batch-size 256
The above YAML file specifies the necessary resources, the location of the code
(workdir), the setup commands to be run before starting the task(e.g.,
installing requirements), and the run commands that designates the actual task
(training a model in this case).
Integrating SkyPilot and DVC
The whole integration is based on the idea of using SkyPilot to run DVC pipelines on cloud instances. To illustrate this, I’ll be using this repository: https://github.com/alex000kim/example-get-started-experiments which already has a DVC pipeline defined it. This particular project solves the problem of segmenting out swimming pools from satellite images. That’s not important for this post as the proposed solution is generic and can be applied to any DVC pipeline and any ML problem. The solution boils down to adding two files to the project:
- a SkyPilot task definition,
sky-config.yaml. - a script that can simplify submitting DVC experiments to a cluster (or a
single instance) provisioned by SkyPilot,
sky-run.py.
Let’s take a look at each of these files in more detail.
sky-config.yaml
expand to see the code
name: sky-run
resources:
accelerators: T4:1
cloud: aws
region: us-east-2
workdir: .
file_mounts:
# if you want be able to interact with your git repos
~/.ssh/id_rsa: ~/.ssh/id_rsa
~/.ssh/id_rsa.pub: ~/.ssh/id_rsa.pub
~/.gitconfig: ~/.gitconfig
setup: | # only executed on `sky launch`
pip install --upgrade pip
pip install -r requirements.txt
# optional nvtop installation if you want to monitor GPU usage
sudo add-apt-repository ppa:flexiondotorg/nvtop -y && sudo apt install nvtop
run: | # executed on `sky launch` or `sky exec`
cd ~/sky_workdir
dvc pull
dvc exp run --pull --allow-missing
dvc exp push origin
The resources section is where you can specify the resources you want to use
for your task. In this case, I’m using a single T4 GPU on AWS. You can also
specify the cloud provider and the region. If you don’t specify the cloud
provider, SkyPilot will automatically pick the cheapest cloud provider for you.
The workdir section is the working directory containing project code that will
be synced to the provisioned instance(s). Its contents are synced to
~/sky_workdir/ on the cluster.
The file_mounts section is where you can specify files that you want to be
available on the instance. In this case, I’m mounting my SSH keys and my git
config so that I can interact with my git repositories from the instance. This
is required here because of the by-design tight integration between DVC and git.
The setup section is where the necessary dependencies are installed.
The run section is where we first navigate to the working directory and then
run the DVC pipeline. The dvc pull command pulls the data from the remote
storage. The dvc exp run command runs the DVC pipeline. The
--pull flag attempts
to download the missing dependencies of stages that need to be run. The
--allow-missing
flag will skip stages with no other changes than missing data.
❗ The dvc exp push origin command pushes the
artifacts of the resulting DVC experiments to git and their data to the
DVC-backed remote storage. Don’t worry about accidentally polluting your git
repository with unintended commits. The implementation of DVC
experiments is pretty clever as it’s
based on git references. That means you’ll be able to cherry-pick the
experiments you’d like to push to your repo.
Now that we have a SkyPilot task definition, we need a way to submit it to a
cluster. It can be done with the following sky launch command:
$ sky launch sky-config.yaml -c mycluster -d -i 5
command output
Task from YAML spec: sky-config.yaml
I 08-10 16:09:38 optimizer.py:636] == Optimizer ==
I 08-10 16:09:38 optimizer.py:659] Estimated cost: $0.5 / hour
I 08-10 16:09:38 optimizer.py:659]
I 08-10 16:09:38 optimizer.py:732] Considered resources (1 node):
I 08-10 16:09:38 optimizer.py:781] ------------------------------------------------------------------------------------------
I 08-10 16:09:38 optimizer.py:781] CLOUD INSTANCE vCPUs Mem(GB) ACCELERATORS REGION/ZONE COST ($) CHOSEN
I 08-10 16:09:38 optimizer.py:781] ------------------------------------------------------------------------------------------
I 08-10 16:09:38 optimizer.py:781] AWS g4dn.xlarge 4 16 T4:1 us-east-2 0.53 ✔
I 08-10 16:09:38 optimizer.py:781] ------------------------------------------------------------------------------------------
I 08-10 16:09:38 optimizer.py:781]
I 08-10 16:09:38 optimizer.py:796] Multiple AWS instances satisfy T4:1. The cheapest AWS(g4dn.xlarge, {'T4': 1}) is considered among:
I 08-10 16:09:38 optimizer.py:796] ['g4dn.xlarge', 'g4dn.2xlarge', 'g4dn.4xlarge', 'g4dn.8xlarge', 'g4dn.16xlarge'].
...
This command will launch an instance on the cluster named mycluster with the
resources specified in sky-config.yaml. The optional -d flag will launch a
cluster with logging detached (i.e., you won’t see the logs in your terminal).
But you can check the logs any time by running sky logs mycluster:
$ sky logs mycluster
command output
Tailing logs of the last job on cluster 'mycluster'...
I 08-10 16:20:15 cloud_vm_ray_backend.py:3261] Job ID not provided. Streaming the logs of the latest job.
I 08-10 20:20:17 log_lib.py:425] Start streaming logs for job 1.
INFO: Tip: use Ctrl-C to exit log streaming (task will not be killed).
INFO: Waiting for task resources on 1 node. This will block if the cluster is full.
INFO: All task resources reserved.
INFO: Reserved IPs: ['172.31.3.57']
(sky-run, pid=26936) A models/model.pkl
(sky-run, pid=26936) A data/test_data/
(sky-run, pid=26936) A data/pool_data/
(sky-run, pid=26936) A data/train_data/
(sky-run, pid=26936) A results/evaluate/plots/images/
(sky-run, pid=26936) 5 files added and 380 files fetched
(sky-run, pid=26936) Reproducing experiment 'rutty-rams'
...
(sky-run, pid=26936)
(sky-run, pid=26936) Ran experiment(s): rutty-rams
(sky-run, pid=26936) Experiment results have been applied to your workspace.
(sky-run, pid=26936)
(sky-run, pid=26936) To promote an experiment to a Git branch run:
(sky-run, pid=26936)
(sky-run, pid=26936) dvc exp branch <exp> <branch>
(sky-run, pid=26936)
(sky-run, pid=26936) Pushed experiment rutty-rams to Git remote 'origin'.
❗Another optional, but highly recommended, -i flag will autostop the cluster
after 5 minutes of idleness. With this, you can allow yourself to forget about
the cluster and not worry about paying for it when you’re not using it.
If you want to run new experiments, you can do so with sky exec:
$ sky exec mycluster sky-config.yaml
command output
Task from YAML spec: sky-config.yaml
Executing task on cluster mycluster...
I 08-10 16:22:24 cloud_vm_ray_backend.py:2683] Syncing workdir (to 1 node): . -> ~/sky_workdir
I 08-10 16:22:24 cloud_vm_ray_backend.py:2691] To view detailed progress: tail -n100 -f ~/sky_logs/sky-2023-08-10-16-22-20-407117/workdir_sync.log
I 08-10 16:22:30 cloud_vm_ray_backend.py:2895] Job submitted with Job ID: 2
I 08-10 20:22:33 log_lib.py:425] Start streaming logs for job 2.
INFO: Tip: use Ctrl-C to exit log streaming (task will not be killed).
INFO: Waiting for task resources on 1 node. This will block if the cluster is full.
INFO: All task resources reserved.
INFO: Reserved IPs: ['172.31.3.57']
(sky-run, pid=27554) Everything is up to date.
(sky-run, pid=27554) Reproducing experiment 'meaty-quey'
(sky-run, pid=27554) 'data/pool_data.dvc' didn't change, skipping
(sky-run, pid=27554) Stage 'data_split' didn't change, skipping
(sky-run, pid=27554) Running stage 'train':
(sky-run, pid=27554) > python src/train.py
...
❗Note how in the above output that DVC is skipping the pipeline stages that don’t need to be executed since nothing about their dependencies changed. So every experiment takes less time to complete while still ensuring complete reproducibility of the final results.
The main difference between sky launch and sky exec is that the latter will
only rerun the steps defined in the run section of sky-config.yaml. This is
useful if you want to run new experiments without having to wait for the setup
section to finish. If, however, you change something about the dependencies of
your project (e.g. requirements.txt), you’ll need to rerun the sky launch
command. It won’t launch a new instance if there’s already one running. We can
also use the sky exec command to run arbitrary commands on the cluster e.g.
sky exec mycluster ls -la ~/sky_workdir/. However, this introduces some
overhead by submitting a new job to the cluster.
❗ So for lightweight commands (like ls), it’s better simply ssh into the
cluster with ssh mycluster (yes, it’s that easy) and do it there. I find it
useful to ssh into the cluster to, for example, monitor GPU usage with nvtop.
Accessing experiment results
Now that we can submit DVC experiments to a cluster, how do we access the results (trained model, plots, metrics, etc.) of the experiments?
❗ Once your SkyPilot job (submitted via either sky launch or sky exec) finishes, you can
download the results to your local machine by running dvc exp pull origin
(replace origin with the name of your git remote if it’s different).
$ dvc exp pull origin
Pulled experiment '['meaty-quey', 'rutty-rams']' from Git remote 'origin'.
To display all experiments available locally, run dvc exp show:
$ dvc exp show
command output
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────>
Experiment Created results/evaluate/metrics.json:dice_multi train.loss eval.loss results/train/metrics.json:dice_multi step >
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────>
workspace - 0.87535 0.027577 0.025258 0.89082 8 >
main 02:57 PM 0.87535 0.027577 0.025258 0.89082 8 >
├── 8168af4 [meaty-quey] 04:25 PM 0.84439 0.053953 0.038985 0.79921 8 >
└── b130150 [rutty-rams] 04:20 PM 0.88954 0.012414 0.021584 0.90234 8 >
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────>
After you compare the experiments and pick the one you want to push to your repository, you’ll have a couple of options:
- apply the experiment to your local workspace via
dvc exp apply:
$ dvc exp apply rutty-rams
Changes for experiment 'rutty-rams' have been applied to your current workspace.
Then you can add-commit-push the changes to your repository. That commit will contain all the changes made by the experiment (e.g. trained model, plots, metrics, etc.).
- alternatively, you can create a new branch out of that experiment via
dvc exp branch:
$ dvc exp branch rutty-rams new-branch
Git branch 'new-branch' has been created from experiment 'rutty-rams'.
To switch to the new branch run:
git checkout new-branch
If you use VS Code, you can perform all the same actions for managing DVC
experiments (dvc exp show/apply/branch/...) in a UI by installing the DVC
extension for VS
Code. It
provides a nice point-and-click interface to compare the results visually.
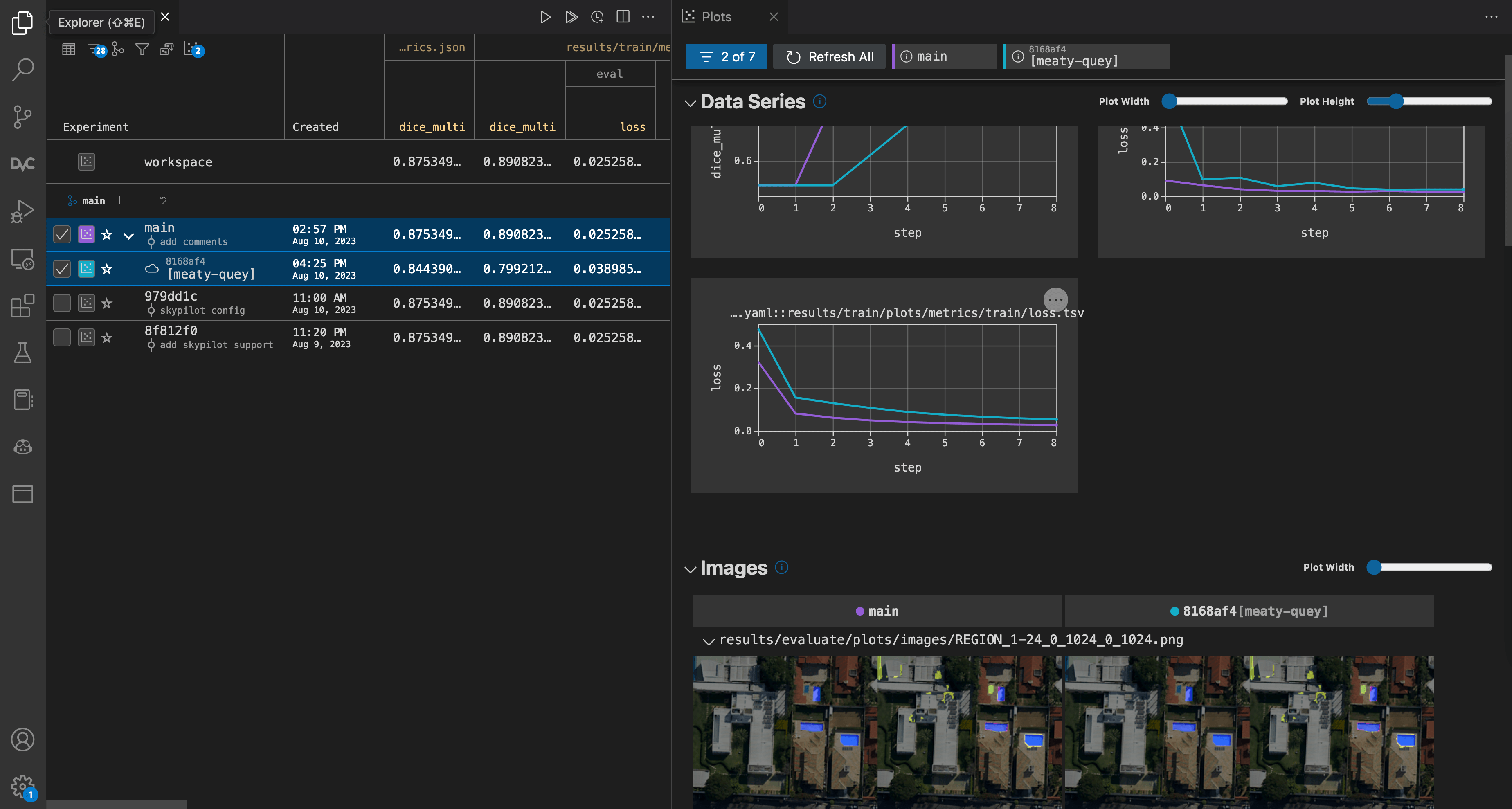 DVC extension for VS Code.
DVC extension for VS Code.We could stop here now that you know how to run DVC experiments on a cluster and
how to access the results. However, I found it a bit inconvenient to have to run
sky status to check if the cluster is running and then decide if I need to
run sky launch or sky exec. Also, I’d have to remember what options they
take and type them out every execution. So I wrote a simple Python script that
does all that for me.
sky-run.py
expand to see the code
import os
import sky
CLUSTER_NAME = 'mycluster'
IDLE_MINUTES_TO_AUTOSTOP = 10
def main(rerun_setup):
task = sky.Task.from_yaml('sky-config.yaml')
# This is optional in case you want to use https://studio.iterative.ai to, for example, monitor your experiments in real-time.
# See: https://dvc.org/doc/studio/user-guide/projects-and-experiments/live-metrics-and-plots
task.update_envs({'DVC_STUDIO_TOKEN': os.getenv('DVC_STUDIO_TOKEN')})
s = sky.status(cluster_names=[CLUSTER_NAME])
print(f'Found {len(s)} cluster(s)')
print(f'Status:\n{s}\n')
if len(s) == 0:
print('Cluster not found, launching cluster')
sky.launch(task,
cluster_name=CLUSTER_NAME,
idle_minutes_to_autostop=10)
elif len(s) == 1 and s[0]['name'] == CLUSTER_NAME:
cluster_status = s[0]['status']
if cluster_status.value == 'UP':
print(f'Cluster is UP, running task (rerun_setup: {rerun_setup})')
if not rerun_setup:
sky.exec(task, cluster_name=CLUSTER_NAME)
else:
# this won't launch a new cluster,
# but will rerun the setup and then the run step
sky.launch(task,
cluster_name=CLUSTER_NAME,
idle_minutes_to_autostop=10)
elif cluster_status.value == 'STOPPED':
print('Cluster is STOPPED, starting cluster')
sky.start(cluster_name=CLUSTER_NAME,
idle_minutes_to_autostop=10)
elif cluster_status.value == 'INIT':
print('Cluster is INIT, waiting for cluster to be ready')
else:
print('Multiple clusters found. Status:')
print(s)
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--rerun-setup', action='store_true')
args = parser.parse_args()
main(rerun_setup=args.rerun_setup)
This script will check if the cluster is running, and if it’s not, it will
launch it. If the cluster is running, it will run the task (i.e. submit the DVC
experiment to the cluster). If you want to rerun the setup step (e.g. to install
updated dependencies), you can pass --rerun-setup to the script. The script
also takes an optional DVC_STUDIO_TOKEN environment variable which you can use
to connect your DVC project to Iterative Studio.
This will allow you to monitor your experiments in real-time (e.g., see the
training metrics and plots as the experiment is running). It’s also possible to
integrate MLflow into a DVC pipeline for experiment tracking as shown
here.
$ python sky-run.py
command output
Found 1 cluster(s)
Status:
[{'name': 'mycluster', 'launched_at': 1691698414, 'handle': ResourceHandle(
cluster_name=mycluster,
head_ip=None,
stable_internal_external_ips=None,
cluster_yaml=/Users/akim/.sky/generated/mycluster.yml,
launched_resources=1x AWS(g4dn.xlarge, {'T4': 1}),
tpu_create_script=None,
tpu_delete_script=None), 'last_use': 'sky exec mycluster sky-config.yaml', 'status': <ClusterStatus.STOPPED: 'STOPPED'>, 'autostop': 5, 'to_down': False, 'owner': [...], 'metadata': {}, 'cluster_hash': '93a26c0a-797b-4ec7-8b85-b7af94734be1'}]
Cluster is STOPPED, starting cluster
I 08-10 16:50:45 cloud_vm_ray_backend.py:1351] To view detailed progress: tail -n100 -f /Users/akim/sky_logs/sky-2023-08-10-16-50-45-233359/provision.log
I 08-10 16:50:45 cloud_vm_ray_backend.py:1180] Cluster 'mycluster' (status: STOPPED) was previously launched in AWS us-east-2. Relaunching in that region.
I 08-10 16:50:45 cloud_vm_ray_backend.py:1704] Launching on AWS us-east-2 (us-east-2a)
I 08-10 16:51:53 cloud_vm_ray_backend.py:1517] Successfully provisioned or found existing VM.
Putting it all together
Now with the sky-run.py script, your workflow will look like this:
Summary
The key benefits of integrating SkyPilot and DVC are:
Simplified ML experimentation workflow - SkyPilot allows launching cloud compute resources easily while DVC organizes experiments and tracks results. Together they streamline the process of iterating on ML experiments.
Automated workflow - SkyPilot’s Python API allows for automatic management of the cluster lifecycle and running experiments based on code changes. This reduces manual steps.
Tracking experiments systematically - DVC tracks code, parameters, datasets, and metrics for each experiment run. This enables comparing experiments and reproducing them.
Easy collaboration - DVC manages smaller files instead of large datasets in Git, enabling sharing and collaboration. SkyPilot allows running experiments on a shared cluster.
Flexibility across clouds - Both SkyPilot and DVC work across AWS, GCP, Azure, etc allowing leveraging any cloud’s resources for experiments.
Efficient use of compute - SkyPilot launches a cluster only when needed and shuts it down when not in use. It also allows us to scale our cluster to meet almost any compute requirements which makes it a great fit for training/fine-tuning very large models (cough… LLMs cough…). DVC caches and reuses computations, avoiding redundant work. This saves time and money.