Training and fine-tuning Large Language Models (LLMs) requires significant computational resources and careful experiment tracking. While many focus on the modeling aspects, efficiently managing compute resources and experiment tracking is equally important for successful ML projects. This guide demonstrates how to leverage SkyPilot and MLflow - two powerful open-source tools - to orchestrate LLM fine-tuning jobs effectively.
An open-source stack for LLM fine-tuning
Modern LLM fine-tuning workflows involve multiple moving parts:
- Resource orchestration across different cloud providers
- Environment setup and dependency management
- Experiment tracking and monitoring
- Distributed training coordination
- System metrics collection
Using SkyPilot for resource orchestration and MLflow for experiment tracking provides an easy-to-use and fully open-source stack for managing these complexities.
We’ll use the LLama-3-1-8B fine-tuning example from Philipp Schmid’s “How to fine-tune open LLMs in 2025” blogpost to demonstrate these tools in action.
Setting Up the Stack
SkyPilot Configuration
💡 Below I’ll be using a kubernetes cluster, however SkyPilot supports virtualy all cloud providers you can think of.
First, install SkyPilot with Kubernetes support using pip:
$ pip install "skypilot[kubernetes]"
Configure your Kubernetes cluster access by ensuring your kubeconfig is properly set up. Then, verify the installation:
$ sky check kubernetes
Checking credentials to enable clouds for SkyPilot.
Kubernetes: enabled
To enable a cloud, follow the hints above and rerun: sky check
If any problems remain, refer to detailed docs at: https://docs.skypilot.co/en/latest/getting-started/installation.html
🎉 Enabled clouds 🎉
✔ Kubernetes
SkyPilot uses a YAML configuration to define jobs. Below the SkyPilot task definition sky.yaml is all that’s needed to kick of our training job on our infra.
# To launch the cluster:
# sky launch -c dev sky.yaml --env-file .env
# To rerun training (i.e. only the "run" section):
# sky exec dev sky.yaml --env-file .env
resources:
cloud: kubernetes # or aws, gcp, azure, and many others
accelerators: H100:8
workdir: . # syncs current directory to ~/sky_workdir/ on the cluster.
envs:
CONFIG_FILE: recipes/llama-3-1-8b-qlora.yaml
# setup step is executed once upon cluster provisioning with `sky launch`
setup: |
sudo apt install nvtop -y
pip install -U -r requirements.txt
FLASH_ATTENTION_SKIP_CUDA_BUILD=TRUE pip install flash-attn --no-build-isolation
python generate_train_dataset.py
# run step is executed for both `sky exec` and `sky launch` commands
run: |
accelerate launch \
--num_processes 8 \
train.py --config $CONFIG_FILE
You can find the rest of the training code and configs in this repository. The details of what’s inside of train.py are beyond the scope of this post. This repository also contains sky_multi_node.yaml, a multi-node version of the sky.yaml file.
MLflow Configuration
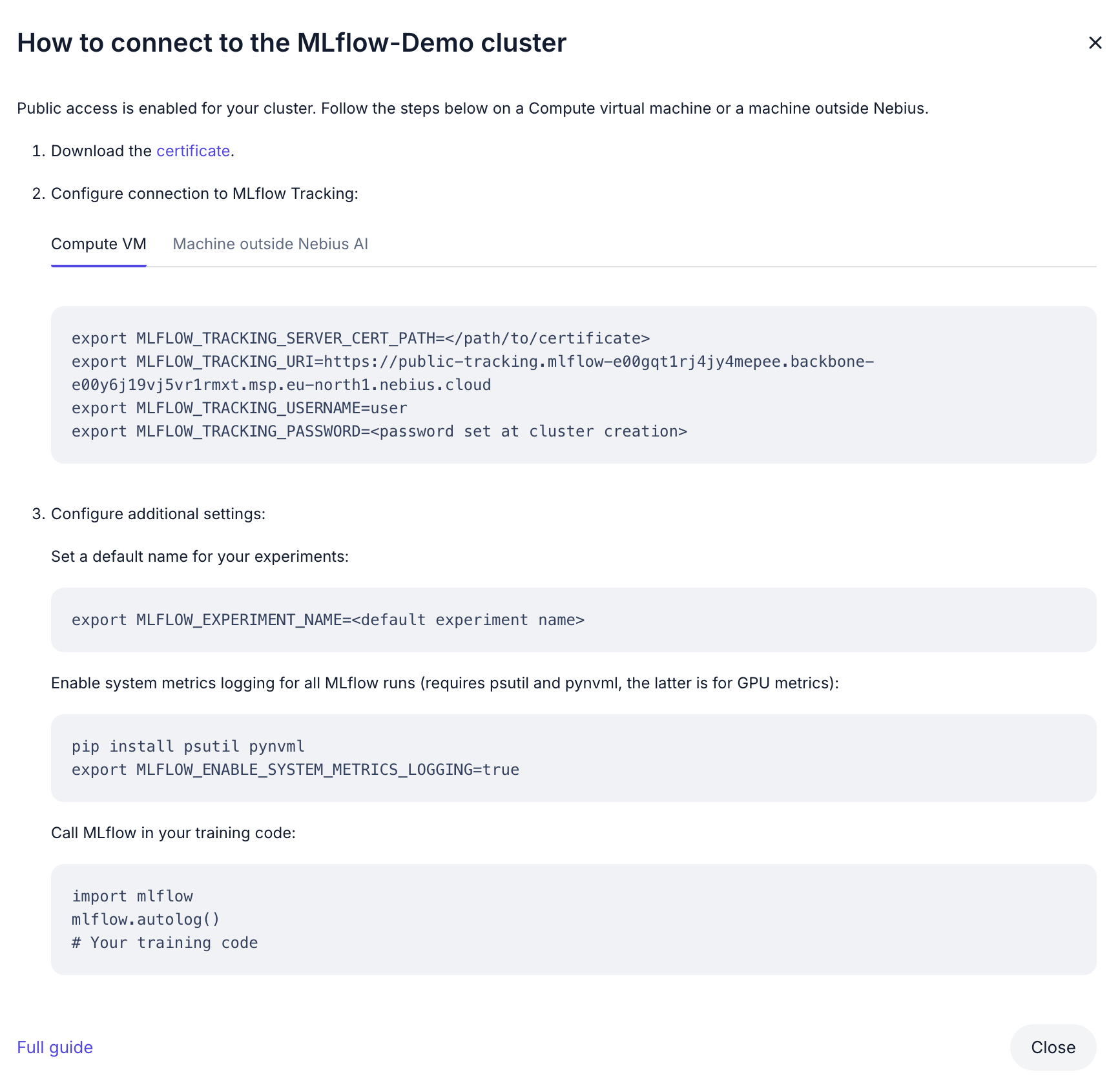
In this example project, MLflow configuration is managed through environment variables. Create a .env file:
# .env
MLFLOW_TRACKING_URI=https://your-mlflow-server
MLFLOW_TRACKING_SERVER_CERT_PATH=/path/to/cert.pem
MLFLOW_ENABLE_SYSTEM_METRICS_LOGGING=true
MLFLOW_EXPERIMENT_NAME=LLM_Fine_Tuning
MLFLOW_TRACKING_USERNAME=your-username
MLFLOW_TRACKING_PASSWORD=your-password
HF_TOKEN=your-huggingface-token
# TEST_MODE=true # Uncomment for development
The MLFLOW_ENABLE_SYSTEM_METRICS_LOGGING=true setting enables collection of system metrics (GPU utilization, memory usage, etc.) but requires additional dependencies:
# requirements.txt
psutil==6.1.1
pynvml==12.0.0
For this tutorial, I used a managed MLflow service from Nebius AI. Setting up the MLflow server instance was straightforward, and they provided all the necessary configuration values to connect with the server.
Kicking Off Training
Once you have your configuration files ready, launching training with SkyPilot is straightforward:
Initial Launch: To provision the cluster and start training for the first time, use:
sky launch -c dev sky.yaml --env-file .envSubsequent Runs: For additional training runs on the same cluster, use:
sky exec dev sky.yaml --env-file .env
While the training is running SkyPilot jobs will be steaming logs into the console:
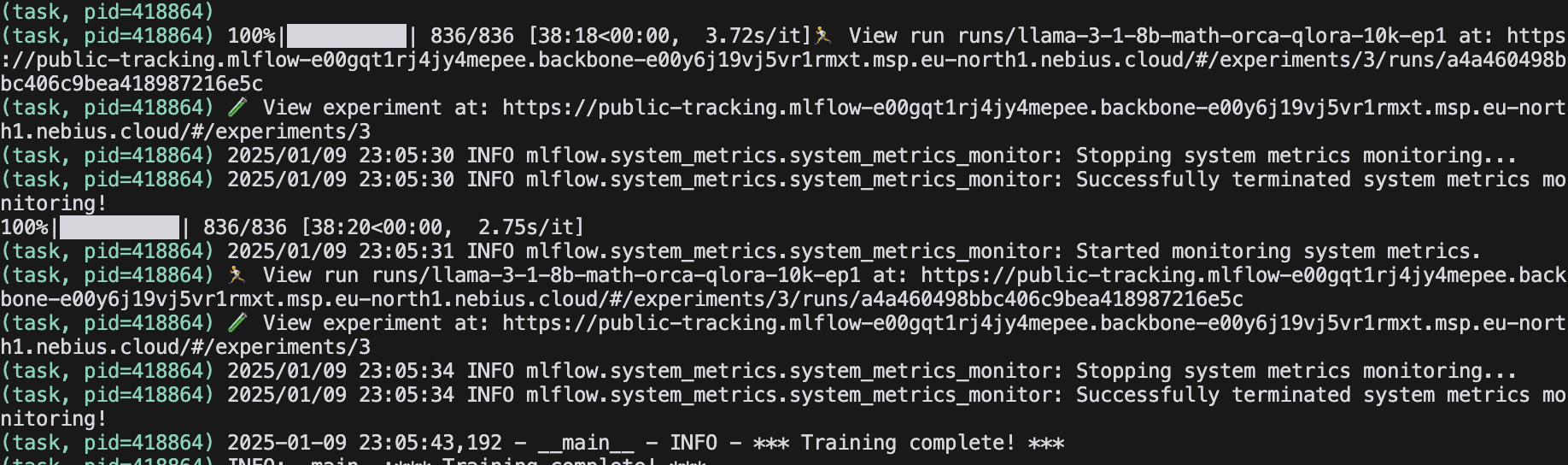
SkyPilot job logs
You can monitor the cluster status using:
sky status
To stop the cluster when training is complete:
sky down dev
For debugging purposes, you can connect to the running cluster via SSH:
ssh dev
MLflow Integration with Distributed Training
In distributed training environments, MLflow logging must be carefully managed to prevent logging conflicts between processes. Multiple processes attempting to log metrics simultaneously can lead to race conditions, duplicate entries, or corrupted logs. Additionally, system metrics need to be properly attributed to individual nodes to maintain accurate monitoring data. Here’s the key integration code:
def train_function(model_args, script_args, training_args):
# Initialize MLflow callback
mlflow_callback = MLflowCallback()
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
callbacks=[mlflow_callback],
)
# Only initialize MLflow on the main process
run_id = None
if trainer.accelerator.is_main_process:
mlflow_callback.setup(training_args, trainer, model)
# Set node ID for system metrics
node_id = trainer.accelerator.process_index
mlflow_callback._ml_flow.system_metrics.set_system_metrics_node_id(node_id)
# Get run ID for post-training logging
run_id = mlflow_callback._ml_flow.active_run().info.run_id
logger.info(f'Run ID: {run_id}')
# Training loop
train_result = trainer.train()
# Post-training metrics logging only on main process
if trainer.accelerator.is_main_process:
if run_id is not None:
metrics = train_result.metrics
train_samples = len(train_dataset)
with mlflow.start_run(run_id=run_id):
mlflow.log_param('train_samples', train_samples)
for key, value in metrics.items():
mlflow.log_metric(key=key, value=value)
Key Considerations for Distributed Training
- Process Management: Only the main process should initialize MLflow runs and log metrics to avoid conflicts.
- Run ID Tracking: The MLflow run ID is stored because
trainer.train()automatically ends its MLflow run when complete. Without capturing the ID beforehand, we wouldn’t be able to log additional metrics after training finishes. - System Metrics: Each node in distributed training needs a unique identifier for system metrics collection
Monitoring Training Progress
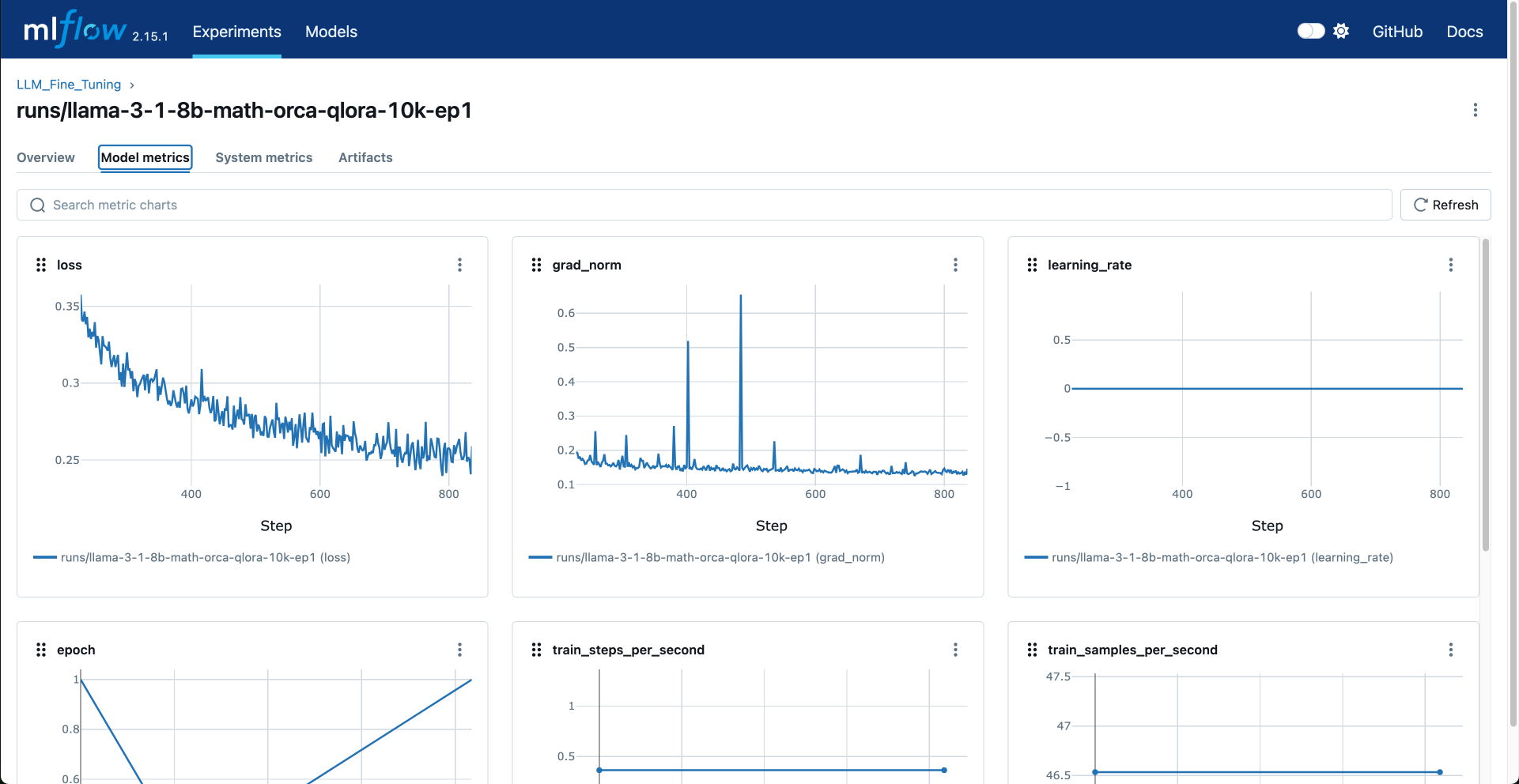
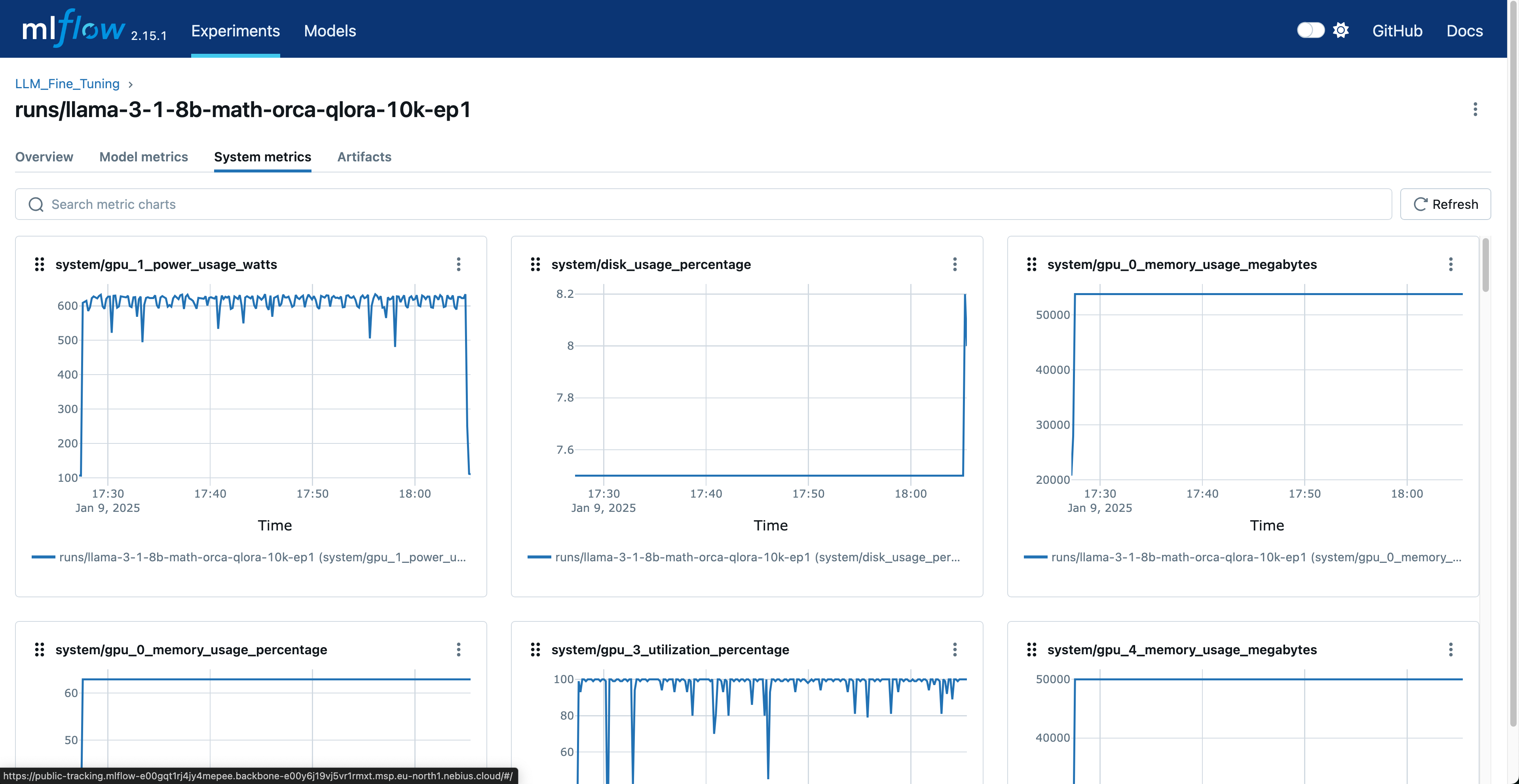
MLflow provides a web UI for monitoring experiments. Key metrics tracked include:
- Training Metrics:
- Loss
- Learning rate
- Batch size
- Training speed (samples/second)
- System Metrics:
- GPU utilization
- GPU memory usage
- CPU utilization
- System memory usage
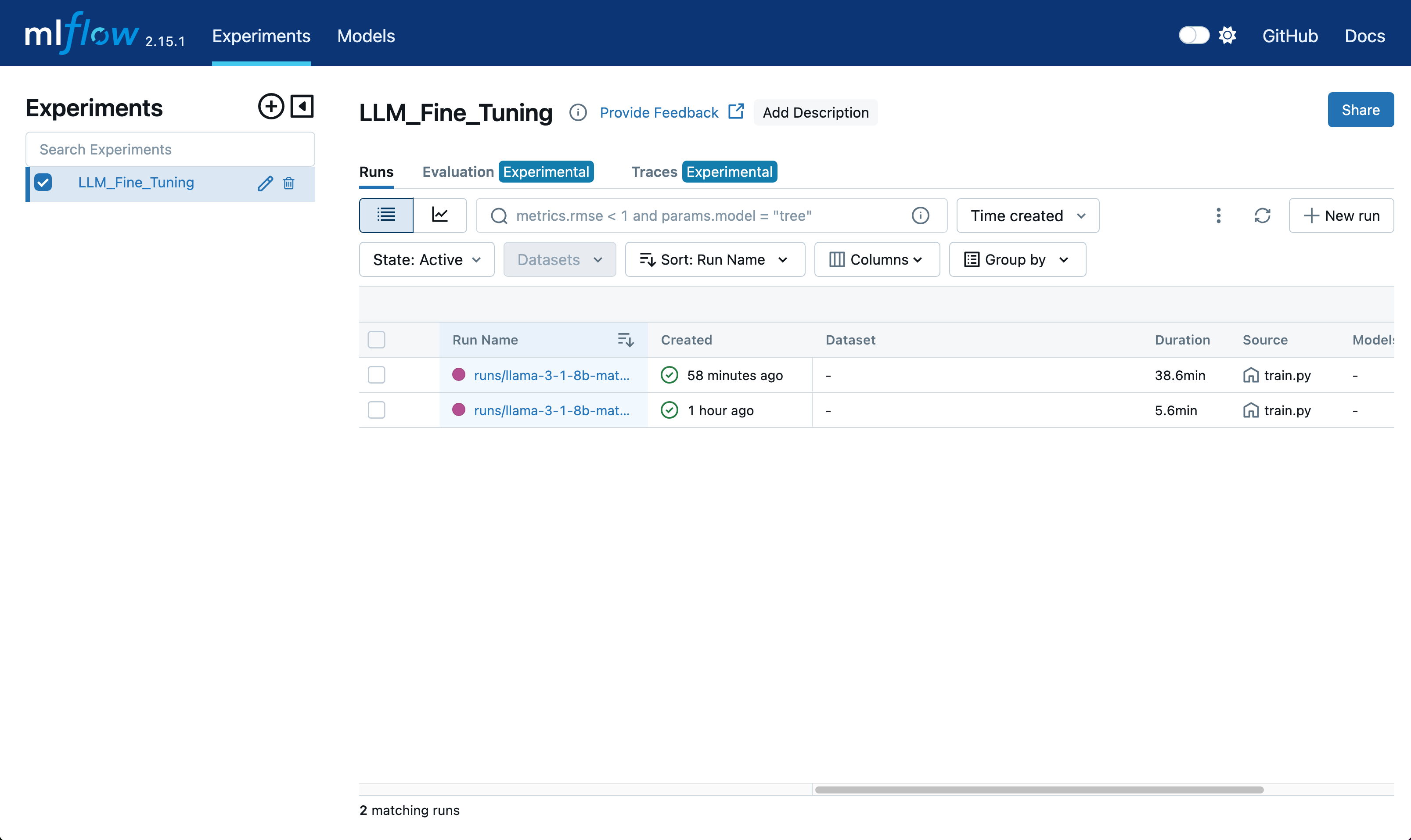
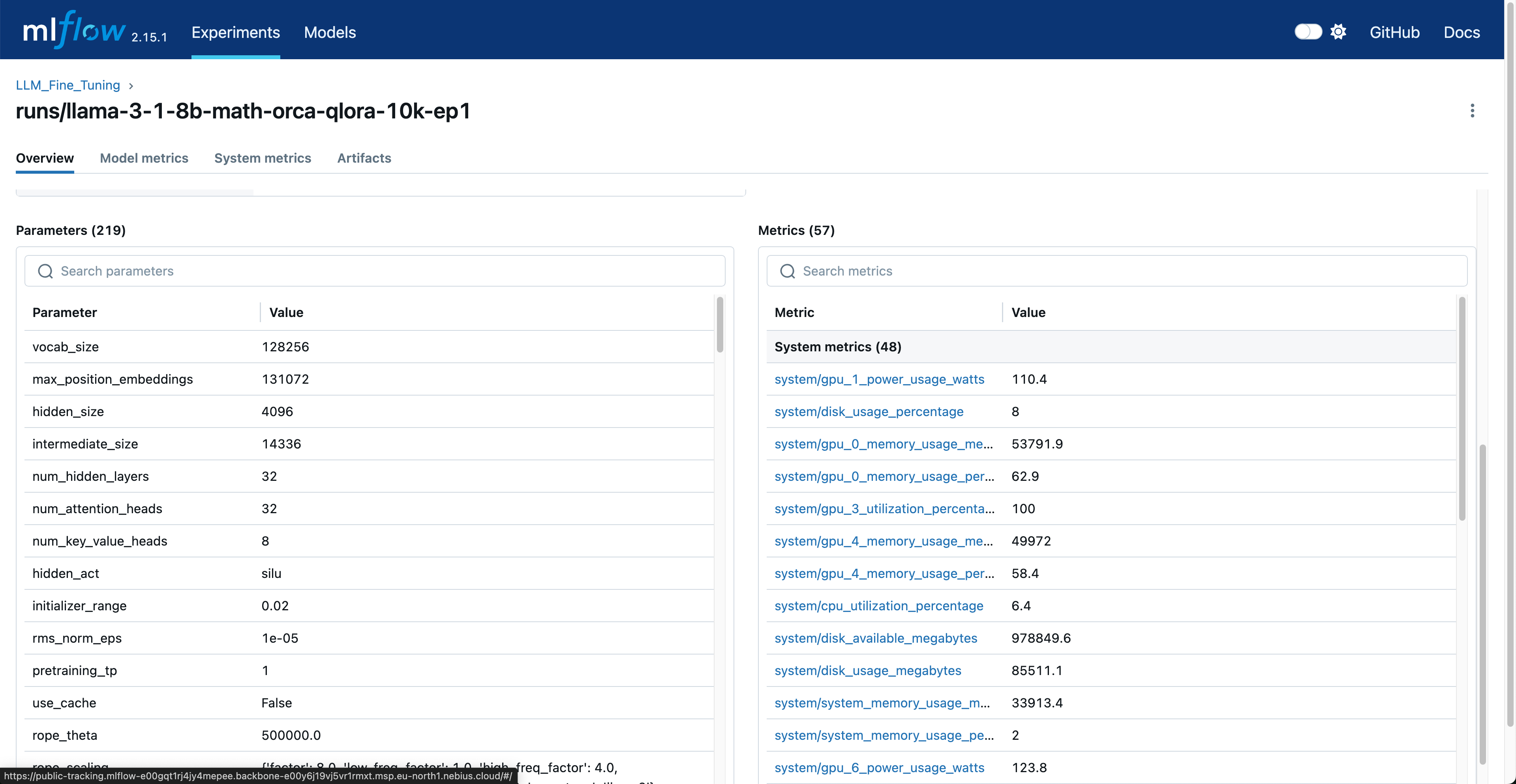
Here’s how to query metrics programmatically assuming you’ve set all required MLflow environment variables:
# query_mlflow.py
import mlflow
def get_training_metrics(run_id):
client = mlflow.MlflowClient()
run = client.get_run(run_id)
metrics = run.data.metrics
params = run.data.params
return metrics, params
if __name__ == "__main__":
run_id = "<your run_id"
metrics, params = get_training_metrics(run_id)
print(f"Metrics: {metrics}")
print(f"Params: {params}")
A Few Best Practices and Tips
- Use a
.envfile for local development - If using HF Accelerate, always check
trainer.accelerator.is_main_processbefore MLflow operations - Monitor system metrics to optimize resource usage
- When using cloud providers, use managed jobs that can automatically recover from any underlying spot preemptions or hardware failures
- Take advantage of
sky queuefor scheduling multiple training runs with different hyperparameters - Utilize
sky logsto access historical job outputs and debugging information
Conclusion
The combination of SkyPilot and MLflow creates a powerful, open-source stack for orchestrating LLM fine-tuning jobs. Key benefits include:
- Flexible resource management across cloud providers
- Comprehensive experiment tracking
- Detailed system metrics monitoring
- Support for distributed training
- Integration with popular ML frameworks
This setup scales seamlessly from single-GPU experiments to large distributed training jobs and can be extended to handle complex workflows.